

音声生成AIの世界:Eleven Labsのボイスクローンと資産とUIになる音声の可能性
自分の声のボイスクローンを作ってみました

最近、音声生成AIをめぐるニュースが相次いでいます。日経新聞は、コンテンツ企業がAIによる「声のクローン」を活用し、声を資産として収益化する動きが広がっていると報じました。SpotifyやTBSといった大手も導入を始めており、新しいクリエイターエコノミーの可能性が注目されています。
一方で、ITmediaは「プリキュア」声優の山村響さんが、自分の声が無断でAIモデルに利用されていたと告発した件を報じました。利便性の裏で、権利や倫理の問題も浮き彫りになっています。
こうした明暗の入り混じるニュースを目にして、「音声AI市場はこれからどう発展するのか?」と気になり調べてみました。その中で目についたのが、急速に存在感を高めている米国のスタートアップ Eleven Labs です。
彼らは「音声は最後のフロントエンドになる」と語ります。つまり、ソフトウェアやサービスを操作する最も自然な方法は、画面やキーボードではなく声になるというのです。
今回のニュースレターでは、Eleven Labsの創業ストーリーや急成長の背景を紹介しながら、「声を資産にする」「声をUIにする」未来を前提に、これからどのようなライフスタイルやプロダクトが生まれるのか、仮説を展開してみたいと思います。

Eleven Labsの創業ストーリー
Eleven Labs の創業ストーリーについては、ポッドキャスト 20VC with Harry Stebbings のインタビューEleven Labs CEO/Co-Founder, Mati Staniszewski: The Untold Story of Europe’s Fastest Growing AI Startup に詳しく語られていました。
Eleven Labsの共同創業者の Mati Staniszewski(Matty)と Piotr “Petr” Dabkowski は、ともにポーランド・ワルシャワで育ちました。彼らは高校時代に出会っています。

大学卒業後、Matty は Palantir に、Petr は Google に所属しつつ、週末にはハッカソン的なプロジェクトに取り組み、暗号資産のリスク分析や推薦システムの試作しいたようです。その中で、音声にまつわる技術的なテーマに惹かれていきます。
転機になったのは 2021 年、ポーランドでいまだに根強く残っていた「映画の吹き替え文化」です。異なる役なのに同じ声で淡々と読み上げられる吹き替え――その不自然さが、彼らに「声の自然な表現」の必要性を強く認識させ、「AIでどうにかできるのではないか」という発想に至るきっかけとなりました。
当初の構想は、YouTuber向けの多言語吹き替え自動化でしたが、実際には市場からの反応は思わしくなく、試行錯誤が続きます。しかしその後、Eleven Labs はナレーションやボイスオーバー生成など、より現実的なニーズに応える方向へとピボットしました。この舵の切り方が、後の急成長の礎になりました。
その後、Eleven Labs は驚異的な速度で成長を遂げます。2023年1月のβ公開から20か月で年換算売上 1億ドルを突破し、さらに10か月弱で2億ドルの年率収益(ARR)に達したと CEO Mati Staniszewski は語っており、現在、同社は年間 3億ドルのARRを年内に達成する見込みとも表明しており、企業と個人・クリエイターからの収益がほぼ50/50に近づくと予測しているといいます。
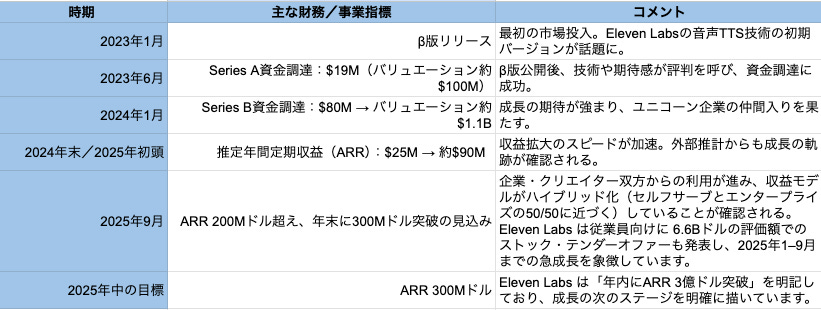
プロダクトと世界観:Eleven Labs は声をどう“再定義”したか
Eleven Labs のプロダクト設計とサービス群を見ると、「声そのものを新しいインターフェース=UI/UXとして捉え直す」という強い設計思想が貫かれていることが見えてきます。
以下、その主要な要素と世界観を整理します。
1. 主な技術モデルと生成プロダクト
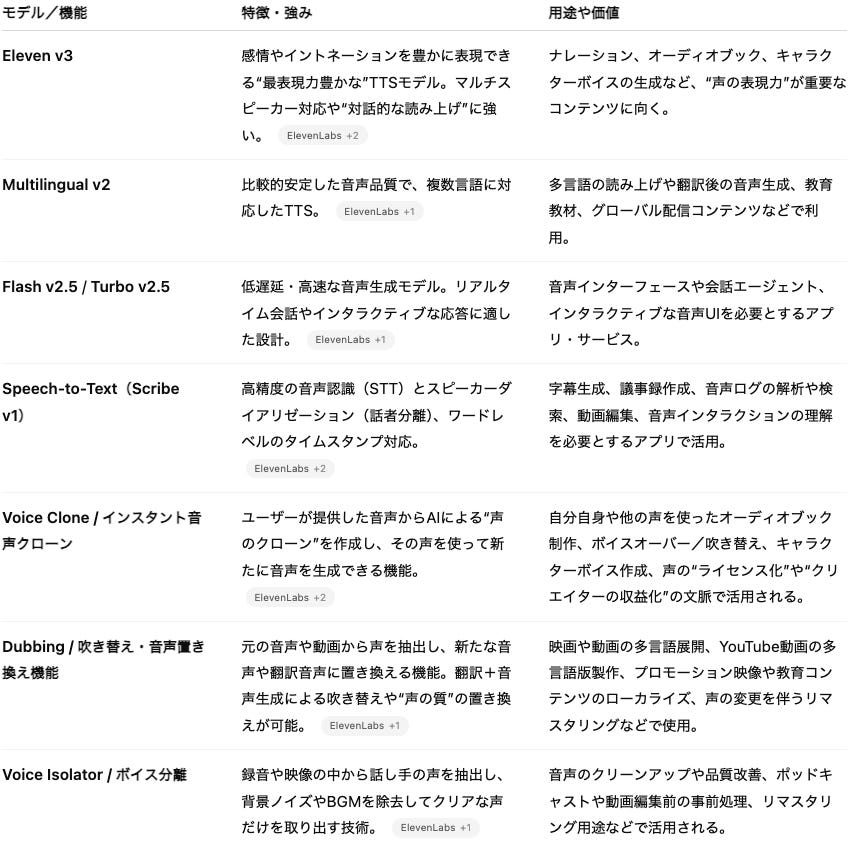
このように、Eleven Labsのプロダクト群は「声を作る(TTS)」「声を聞き取る(STT)」「声を模倣・再現する(声のクローン)」「声を置き換える/再翻訳する(吹き替え)」といった複数のレイヤーをカバーしており、声という素材を起点に多様な変換・生成・再構築が可能なプラットフォームとして設計されています。
以下の動画では、Eleven V3を用いて、3人のスピーカーに生成したポッドキャスト番組を読み上げさせるプロトタイプアプリを作成している動画です。話し方のテイストも選択すると、「興奮しているような」や「興味津々に」など、テンションまで操作することができ自然な音声が再生されています。
ボイス・クローンを作成する方法
Voiceクローンは、Eleven Labsプラットフォームに雑音のない声を数分から数時間分アップロードすることで、その音声を解析し、そっくりな声色を作ることができるサービスです。
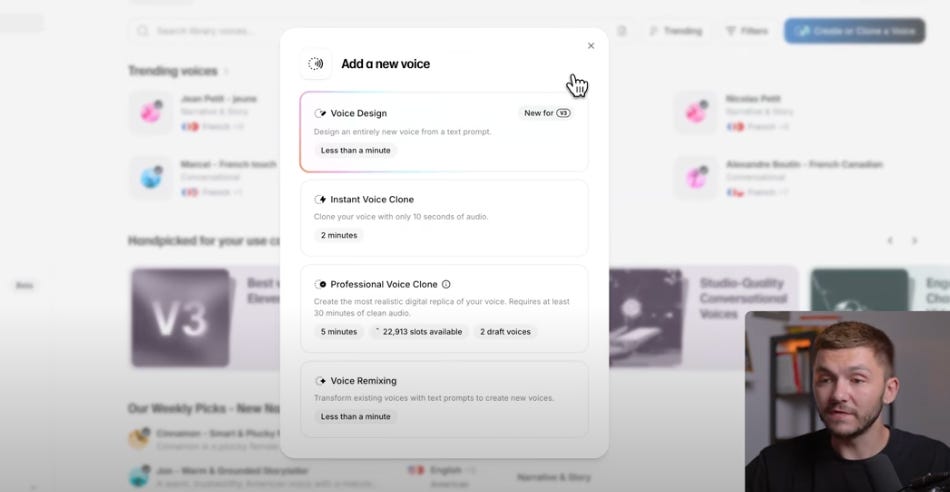
使用するには、月数ドルの有料プラン契約が必要ですが、以下の動画でどんなクオリティなのか確認できます。驚くほど、再現性の高いクローンが生成されています。
クローンの際には、すでに録音した音声をアップロードするか、プラットフォームで録音をしてそのまま仕様することもできます。
試しに、プランに加入してクローンを生成してみました。
どんな精度か是非試してみてください。普段の声はPodcastをお聞きいただけると、fastモードなのでやや違和感はありますが、そこそこ自分でも似ている声のクローンを作ることができたと思います笑
2. 世界観としての「声のUI」/「声の経済」
Eleven Labsが掲げる世界観には、“声そのものがUIであり、声そのものが価値(資産)になる”という二つの柱が存在します。
従来、ユーザーインターフェースは画面やタップ、文字入力などが中心でしたが、Eleven Labsは「声(音声)」をインターフェースに据えることで、声と対話するような体験がUIになる未来を描いています。対話、ナレーション、返答、コマンドなど、すべて声のやりとりで完結する世界です。
たとえば、低遅延TTSモデルやAgentプラットフォームは、音声で問いかけて返答を得るような自然なインタラクションの実現を目指しています。
一方で、声を資産/クリエイターの収益源として再定義することも見据えていると考えられます。“声のクローン”機能を通して、プロの声優だけでなく、一般のクリエイターや個人も「自分の声」を生成・ライセンスして収益化できるようになる可能性が提示されています。声そのものが“IP(知的財産)”になり得る、という考え方です。
この世界観は、日経記事でも指摘された「声のクリエイターエコノミー」の未来や、Eleven Labsが提供する従業員向けストック・テンダー制度を通じた“声や技術の所有と価値化”の議論と重なります。
ただし、声が唯一のUIになるというよりも、有力な選択肢としてこれから勢いが増してくる、と捉える方がいいかとは思います。なぜなら、実際にはタイピングやマウス操作した方が圧倒的に楽で素早い場合もあるからです。
しかしながら、今は声によるUIは過小評価されているのではないかと思うのです。
考察:声は最後のフロントエンドとなるのか
Eleven Labs のストーリーとプロダクト群をたどると、彼らが描く未来像はシンプルかつ大胆です。
「声は資産になり、声はUIになる」。
この二つの軸を起点に、私たちのライフスタイルやビジネスはどのように変化するのでしょうか。
以下のように整理してみました。
声が資産でありUIになる世界

声は本当に資産になるのか?
自分の声をクローン化し、収益を得られる世界は面白い一方で、権利や本人同意が整わなければリスクの方が大きいでしょう。声が資産として流通するためには、「誰の声かを証明する仕組み」と「利用範囲の明示」が欠かせません。
音声UIはどのシーンで主役になるのか?
すべてが音声UIに置き換わる未来は現実的ではありません。ただ、運転中や家事の最中など、手や目を奪われる場面では音声が最も自然なインターフェースです。逆に、精密な操作や複雑な情報整理は依然として画面が優位です。つまり、音声は「最後のフロントエンドのひとつ」として、状況に応じて活躍するでしょう。
自動化と人間らしさのバランスはどう取るか?
顧客対応や日常の手続きが音声エージェントで完結する未来は便利です。しかし、人間ならではの共感や臨機応変さは、まだAIには難しい部分です。自動化が進むほど、むしろ「ここは人間が応じる」という線引きが重要になります。
Eleven Labs の物語は、ただのスタートアップの成功譚ではありません。
それは、声を資産とし、声をUIとする未来のプロトタイプです。
ぼく自身は、音声がすべてを置き換えるとは思っていません。けれども、生活の中で「ここは声が一番自然」という場面は確実に増えます。そこに向けて、Eleven Labs のように声の表現力や遅延の課題に真正面から取り組む企業が、次の体験の標準を形づくっていくでしょう。
しかしながら、OpenAIなども音声に特化したモデルを発表しており、クローン生成などもまだ発表されていないため、この市場はまさにこれから熱くなってくるのではと思います。
とはいえ、この技術をどう使うかを考えることがよほど重要です。つまり、
「自分の声をどう扱うか?」「声を前提にしたUIをどう設計するか?」
この二つの問いにどう向き合うかが、これからの技術とビジネス、そしてぼくらの日常を大きく変えていくのだと思います。
今回は以上です。
このニュースレターが役に立ったらXで共有してください。質問や感想は返信で受け付けます。
では、また👋
Lawrence
あまりの自然な声の再現に驚きました!やってみたい気持ちになったので、時間確保してトライしてみます
万能ではないけれど、最も人間的で自然なUI。
配信者として声でつながる体験を積み重ねることが、未来の標準になる気がします。