

DeepSeekショックは、ジェボンズのパラドックスを生むか、それともスプートニクショックか
本当にNVIDIAを揺るがすほどのAI業界へのイノベーションなのか?

スプートニク・ショックとは、1957年10月4日のソ連による人類初の人工衛星「スプートニク1号」の打ち上げ成功の報により、アメリカ合衆国を始めとする西側諸国の政府や社会が受けた衝撃感、さらに危機意識を指す ─ wikipedia
ジェボンズのパラドックスが再び発生しました。AI がより効率的かつアクセスしやすくなるにつれて、その使用は急増し、私たちにとってはいくらあっても足りないほどの商品に変わっていくでしょう。 ─ Satya Nadella
DeepSeek R1が、株式市場に大きな衝撃を与えているというニュースが出ました。
NVIDIA株は17%安(1日で90兆円も減った)、NASDAQは3%安でAI関連銘柄を中心に暴落し、DeepSeekショックといわれています。

R1を紹介した際に、ここまでの影響が出るとは、正直予想外でした。

ニュースによれば、今回の暴落は「DeepSeekが低コストかつ高性能なモデルをわずか500万ドル程度で実現してしまったこと」によって、AIへの投資価値そのものが疑問視された結果だということのようです。
正直なところ、私にはまだ腑に落ちていません。読者の皆さんの中にも、同じような疑問を抱いている方がいるのではないでしょうか。
そもそも、DeepSeekの成功をOpenAIなどの先端AI企業は再現できないのか?
これは、本当にNVIDIA株を揺るがすほどのイノベーションなのか?
そこで今回は、上記の問いに対する私の結論を書いてみたいと思います。
✍️ Table of Contents
そもそも、DeepSeekの成功をOpenAIなどの先端AI企業は再現できないのか?
DeepSeekが成功した技術的背景とは何か
OpenAIやAnthropicはこの手法を模倣し、低コストモデルを作れるのか?
これは、本当にNVIDIA株を揺るがすほどのイノベーションなのか?
DeepSeekの手法が再現できるとして、本当に高性能GPUは不要なのか?
NVIDIAの優位性はGPUの需要だけなのか?
結論
短期的な影響
長期的な影響
DeepSeekショックは、ジェボンズのパラドックスを生むか、それともスプートニクショックか

そもそも、DeepSeekの成功をOpenAIなどの先端AI企業は再現できないのか?
これをできるだけ正確に考えるためには、DeepSeekの技術的背景を利用する必要がありそうです。
ただし、公開されている論文の情報に”嘘”がないことを前提に考えています。
DeepSeekが成功した技術的背景とは何か
DeepSeek R1は、特定の領域でOpenAI o1を凌駕する性能を誇り、コストも少なくとも20分の1位で利用できるモデルといわれます。
DeepSeekの技術的な優位性を理解するためには、前モデルのV3を理解する必要があります。R1はV3で進化した技術を応用した成果だからです。
DeepSeekのV3での技術的ブレークスルーには、大きく以下の2点が挙げられます。それは、DeepSeek MoE (Mixture of Experts)とDeepSeek MLA (Multi-head Latent Attention)です。
1.DeepSeek MoE (Mixture of Experts)
従来の大規模モデル(ChatGPTなど)では、推論時にモデル全体をフル活用してしまうため、不要なパラメータ計算が膨大になる傾向があったそうです。
DeepSeek MoEは、複数の「エキスパート(専門領域)」を持つモジュール構造を導入し、必要なエキスパートのみを選択して計算することで計算効率を高めると同時に、ロードバランスや通信量を最適化する仕組みを確立することに成功したといいます。
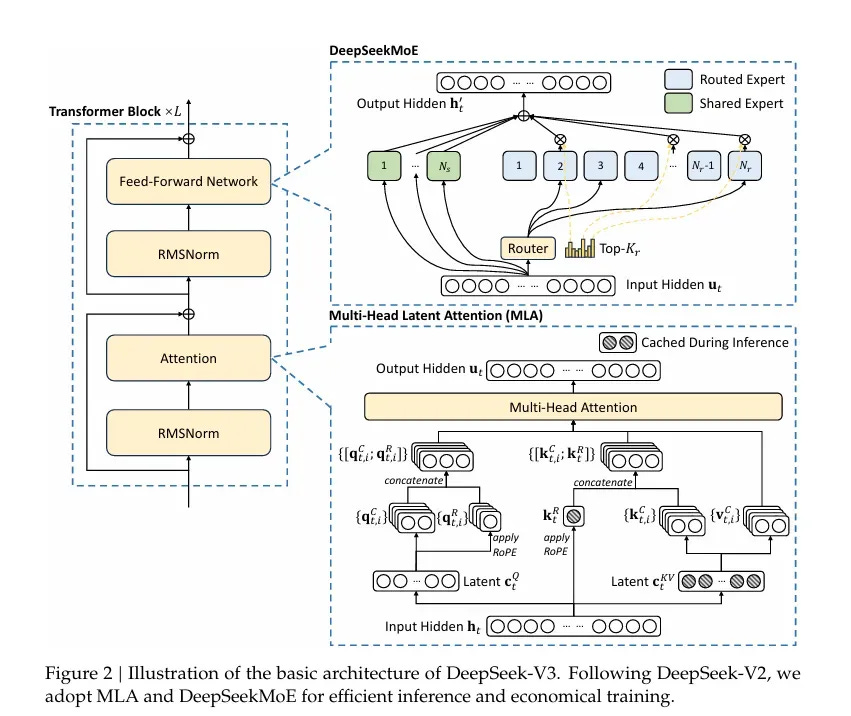
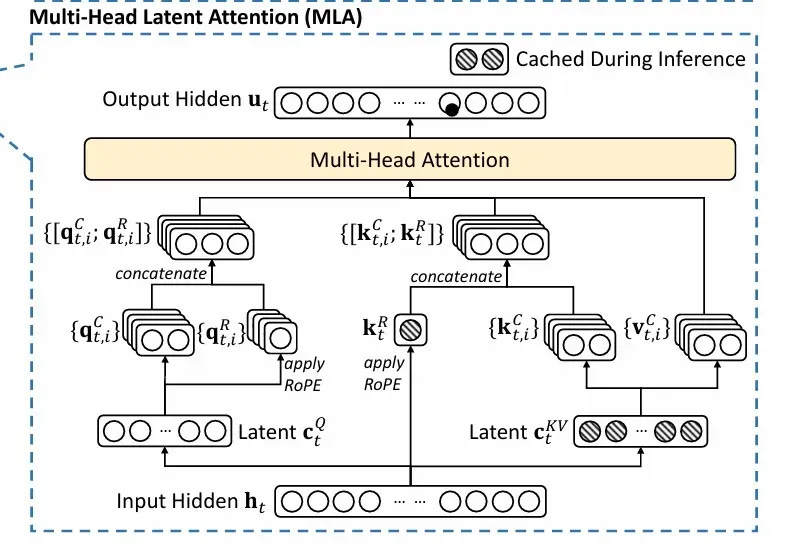
2.DeepSeek MLA (Multi-head Latent Attention)
コンテキストウィンドウが巨大化すると、キー・バリューのペアをすべてメモリに載せる必要があり、メモリ使用量が増大します。
DeepSeek MLAは、キーとバリューを圧縮表現で扱う工夫により、少ないメモリで長いコンテキストを扱うことを可能にし、推論コストを削減することに成功したといいます。
H800前提の徹底最適化(PTXレベルでのチューニング)
米国の対中輸出規制により、NVIDIAのハイエンドGPU(H100等)をそのまま使えない環境下で、敢えてメモリ帯域が制限された「H800」を用い、CUDAのさらに下位レイヤーであるPTX(アセンブリ)を直接最適化するという極端な手法を導入したそうです。
H800のみで世界最先端クラスの学習を回せるソフトウェアアーキテクチャを構築したことが、DeepSeekの最大の特徴とも言えます。
DeepSeek-R1-Zeroから「DeepSeek R1」へ
DeepSeek-V3-Baseに対し、教師データ(SFT:Supervised Fine-Tuning)を一切使わずに、数学問題の「正答報酬」だけを与えて回してみた結果、モデル自身が「段階的に問題を解き明かす」高度な思考プロセスを自律的に学習し始めたことが判明しました。
これは、前の記事で「アハ体験」と説明した部分です。
DeepSeek-R1-Zeroが示唆した「強化学習のみでも、モデルは自律的に思考を獲得する」という結果を受け、次はSFTを組み合わせた完全版を作ろう、というモチベーションで開発されたのがDeepSeek R1でした。
これまでのLLM開発では、AIのみ自律的学習だけでなく、人間が推論プロセスやパターンなどの教師データを与えながら学習をさせていくのが一般的だったようです。
R1では、Zeroの課題であった以下のような問題も解消することに成功しました。
コールドスタート問題を緩和するために、あらかじめ少量のCoT(Chain-of-Thought)データを作成し、これでV3-Baseをある程度「長考の形式」に慣らした状態に調整
その後で強化学習を行うことで、報酬を獲得しやすい初期状態を作り、学習の安定性を高めた
SFTのデータセットでは「人間が読める形(Markdown形式や要約付きなど)を意識」しており、言語混在や可読性の問題を大幅に緩和した
R1では、
まずは数千件のCoTデータでSFTし、コールドスタートを改善
次に「思考タスク(数学、ロジック、コード)」などはルールベース報酬で強化学習
一般的なQA/ライティング/ロールプレイ等は別途報酬モデルを作り、それによって汎用タスクの性能も合わせて向上させる
さらに再度SFTを行い、モデルを人間にとって使いやすい出力形式へ再調整する
というプロセスを経て、いわば強化学習とSFTの反復を行うことで、「思考力」と「可読性・汎用性」を高いレベルで両立するDeepSeek R1が完成したといわれています。これらはV3、R1のホワイトペーパーで全て公開されているロジックです。
OpenAIやAnthropicはこの手法を模倣し、低コストモデルを作れるのか?
結論としては「技術的には再現可能だが、必ずしもすぐに行われるわけではない」と考えられます。
DeepSeekが詳細をオープンにしているため、MoEやMLAを駆使した低コスト学習、PTXレベルのチューニング、そして強化学習+SFTの反復による高い推論能力の獲得は、理論上は他社でも真似できるはずです。
しかし、
そもそも高性能GPUを大量に使える(H100やTPUなど)企業であれば、「やや面倒な最適化をしなくても大規模クラスターで回せる」
蒸留(既にあるモデルチューニングして新たなLLMを抽出する行為)される“教師役”になるだけの最先端モデル(例えばGPT-4oクラス)を保持している企業は、むしろ先行している立場
モデル提供ビジネス上、学習を効率化しすぎると収益を得にくいという側面も考慮せねばならない
などの要因から、DeepSeekほど急進的な最適化に踏み切るインセンティブが今は薄い可能性があると思います。
これは、本当にNVIDIA株を揺るがすほどのイノベーションなのか?
現在、NVIDIAはAIブームの最大の受益企業として、市場評価(株価)が非常に高い水準にあったといわれています。
ジェフリー・エマニュエル氏(元ヘッジファンド・アナリスト兼AIエンジニア)の指摘によると、この背景には「AI分野での爆発的需要」「データセンター向けハイエンドGPUの高い市場独占力」がある一方で、「株価が期待成長をはるかに織り込みすぎている」という懸念もあるとされています。
NVIDIAの強みは“GPUハード”だけではない
CUDAエコシステム
GPU向けのローレベル言語であるCUDAを中心に、PyTorchやTensorFlowといった主要AIフレームワークが最適化されており、「GPUでAIを動かすならNVIDIA製」という事実上のデファクトスタンダードを築いてきました。
2.インターコネクト技術(Mellanox買収)
大規模クラスタでGPU同士を結びつけ、データを効率的にやり取りし続けるための超高速通信技術を押さえていることも大きな参入障壁です。
3.“超過利潤”を再投資するフライホイール
ハイエンドGPUの高い粗利(90%前後)をR&Dに回し、さらなる製品性能向上を図ることで、競合他社との差を拡大し続けてきました。
これらによってNVIDIAは、AMD等の他社GPU勢との差を大きく広げてきたわけですが、膨大な投資がAI市場に一斉に流れ込む中、NVIDIAの“独走”がいつまでも続くのか?という疑問は年々大きくなっています。
ジェフリー・エマニュエル氏は、NVIDIAが抱える大きな脅威を指摘しています。特にDeepSeekに関しては、NVIDIAのGPU需要と“超高収益”構造に影響しうるとしています。
大幅なコスト削減:およそ1/20の計算資源で同等性能
DeepSeekは、H800という制限付きGPUでありながら、FP8の導入やMoE、MLAなどを駆使して圧倒的に安価かつ高性能な学習パイプラインを実装しました。
この事実は、「従来のAIラボは過大なGPU投資をしていたのでは」という疑念を呼び、業界全体の「必要GPU量」の前提を覆しかねない。
DeepSeekがAPI利用料をOpenAIの数十分の1以下で提供できるのは、単に「安売り」だからでなく、推論効率の大幅な向上があるからだとみられています。
従来、NVIDIAが主張してきた「高価なGPUを使わないと先端モデルの推論は難しい」という暗黙の前提が崩れる可能性があり、市場の不安を増幅させました。
これらの要因が重なると、NVIDIAが想定していたほどにはGPU需要が伸びない、もしくは競合・自社内製チップに置き換えられるリスクが顕在化してきます。エマニュエル氏は「NVIDIAは20~30倍もの将来売上を株価に織り込んでいるが、少しでも成長ペースやマージンが下振れすれば、過剰に楽観的なバリュエーションが揺らぐ」と指摘します。
とはいえ、効率化と低コスト化は不可避の流れ
今後、AI分野がさらに進展しモデルがコモディティ化してくると、「より低いリソースで高度な推論を実現する」 手法の重要性は高まります。
OpenAIなども結局は、ディスラプションを回避するために、DeepSeekの手法を研究し、自社版の最適化を進める可能性が十分にあると思われます。
DeepSeekの手法が再現できるとして、本当に高性能GPUは完全に不要なのか?
短期的には巨大需要が続く見通しも
ジェボンズ・パラドックス的に、AI推論や学習が安価になるほど適用分野が急拡大し、トータルの計算需要はむしろ増大するシナリオがあります。

Chain-of-Thoughtモデルでの推論コストは上昇しがちなので、大規模GPUクラスタは依然必要との見方も根強いらしいです。
特にメタやMicrosoftなどの巨大企業は、当面は「時間を金で買う」方が合理的な場合が多く、「最新GPUを何十万枚も買う」という選択肢を取りやすいはずです。
しかし、超高マージンがいつまでも続く保証はない
DeepSeekが証明したように、MoEやMLAによる通信効率向上・メモリ負荷低減の手法が一般化すれば、「ハイエンドGPUを大量投入するしかない」という前提が崩壊することは十分あり得ることがいわれてます。
エマニュエル氏の論点として、NVIDIA株は「企業価値が将来10倍以上になる」というレベルの楽観を既に織り込んでいるが、
思ったほどの需要爆発が起こらないシナリオ
競合・自社チップ・代替ハードウェアへのシフト
大規模モデルの効率化により、(一社当たり)必要GPU台数が大幅に減る展開
などが重なれば、売上高予想・粗利率ともに揺らぐ。仮にこれらが少しでも現実化すれば、株価が急落するリスクは無視できないと結論付けています。
また、CerebrasやGroqのようなスタートアップは、従来のGPU設計とは全く異なるアーキテクチャでインターコネクトの問題を根本的に回避する手法を追求しており、GoogleはTPUを、AmazonはTrainium/Inferentiaを、MetaやMicrosoft、Appleもそれぞれ独自チップを開発しています。
大口顧客(ハイパースケーラー)ほどNVIDIAからの調達コストを削減したくなるインセンティブが働くため、中長期的にはNVIDIAの主要収益源である「データセンター向けハイエンドGPU」需要が減少するリスクがあるともいえます。
結論
結論としては、「不要論」は早計だが、リスクは無視できないと思います。短期的な影響と長期的な影響に分けて整理します。
短期的な影響
DeepSeek R1の衝撃は確かにセンセーショナルだった。しかし、必ずしもOpenAIやAnthropicなどのAI企業が太刀打ちできない技術というわけではないため、DeepSeekショックは短期的に直接的な市場支配を意味しない。
ただし、AI推論需要の「爆発的拡大」を予想する見方も有力で、NVIDIAが完全に不要になるわけではない。
依然としてハイパースケーラー(Microsoft、Meta、Googleなど)の莫大な投資が続くため、NVIDIAのデータセンター向けGPU出荷台数は膨れ上がる可能性がある。
長期的な影響
DeepSeekのような効率化技術、Cerebras/Groqなど独創的アーキテクチャ、さらにはCUDAロックインの解体につながるソフトウェア抽象化の波が大きくなれば、NVIDIAの圧倒的収益力(高マージン)を蝕む可能性がある。
ただし、AI普及がもたらす総体的な需要拡大も予想され、不確実性が増す一方で、「GPU需要自体が衰退するわけではない」という二面性がある。
DeepSeek型の徹底的な最適化手法が台頭すれば、NVIDIAの独占的地位が徐々に揺らぐリスクはより現実的になる。
以上のように、NVIDIAが直面する状況は複雑で、短期的な株価維持と長期的な競争優位の行方は一筋縄ではいきません。
エマニュエル氏のように「長期ではAI自体は莫大なインパクトをもたらすが、それを一社が総取りできるほど単純な構図ではない」という見解は、DeepSeekや他の競合ハードウェア、ソフトウェアの動向を踏まえると説得力があるように思います。
推奨するわけではありませんが、NVIDIA株は底値での短期的な買い増しはあり得る一方、長期的には徐々に売却していく、という提案アクションが考えられそうです。
今回は以上です。
では、また👋
参考記事
読者の反応を見ながらコンテンツの方向性や文量、更新頻度を改善しています。ぜひリアクションいただけたら嬉しいです。
タイムリー且つ、分かりやすい考察、いつも感銘を受けてます!
良記事ありがとうございます。